Search Engine
•
Image Search Engine
A reverse image search engine for fast meme search
Tech stack: Daisy UI, DuckDB, FastAPI, Jinja, Python, PyTorch, and TailwindCSS
Update:
- Changed the image feature extraction model from the smaller model to the larger model for better image feature extraction.
- Reduced image features dimensionality using PCA to speed up the search process and reduce memory usage.
- Incorporated DuckDB to store the image features and the image paths to improve the search speed.
- Enabled keyword search to find images based on image descriptions.
TL;DR: An image search engine powered by ResNet, allowing users to upload an image and instantly retrieve similar matches from its database, leveraging cosine similarity and PCA for efficient feature extraction and rapid search results.
Introduction

I present you an image search engine capable of extracting image featues with the pre-trained neural network model and retrieving similar images from a dataset of memes.
The UI is made using Jinja2 templates for simplicity and TailwindCSS for quick styling. The backend uses FastAPI as it’s lightweight and easy to use. As for the deep learning framework, I chose PyTorch because its API is easy to use and well-written documentation. Most importantly, many pre-trained models are also installed with it. For the backend database, I chose DuckDB because of its speed and plugins support.
How It Works?
Reverse Image Search
The image search engine allows users to find images in the database using a single image.
Once the query image is uploaded, the system would preprocess the image and extract its
features with a modified ResNet model and represent them in a -dimensional vector.
Finally, the distance between the query image’s feature vector and the feature vectors of all images in the database is calculated using cosine similarity. The distance is represented in a range of to , with indicating not identical and indicating identical.
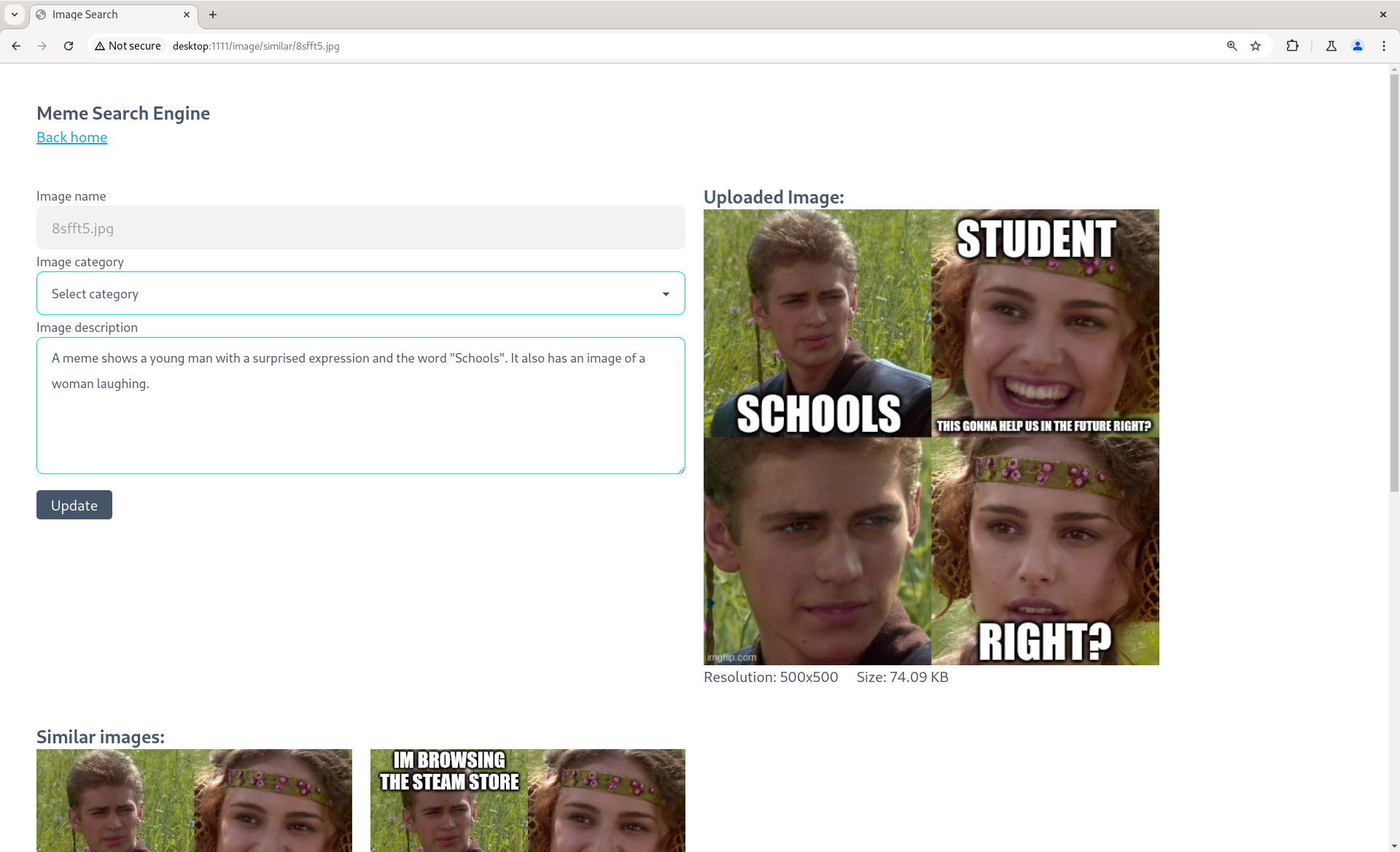
Keyword Search
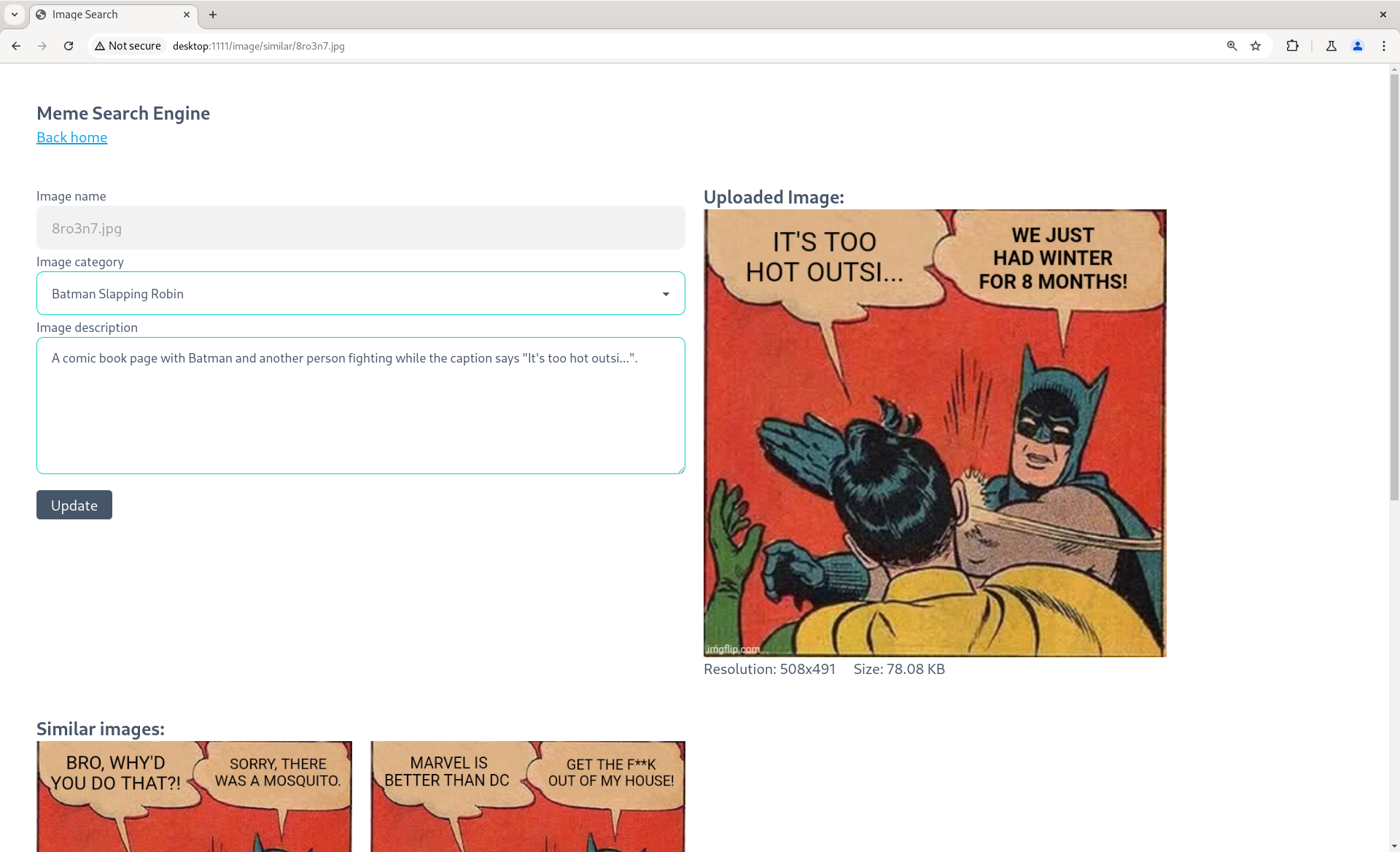
Every image that gets uploaded to the search engine will be assigned a description using a multi-modal language model before being stored in the database. This allows users to search for images based on their descriptions.
When users input keywords into the search bar, the search engine will turn the keywords into an embedding vector and compare it with the embedding vectors of the image descriptions in the database. The closer the distance between the keyword embedding vector and the image description embedding vector, the more relevant the image is.
Improvements
Accurate Feature Extractions
I decided to use ResNet50 since it’s capable to capturing
more complex features in the images compared to ResNet18.
However, it requires more memory and computational power.
On the other hand, the search engine will be able
to provide more accurate results.
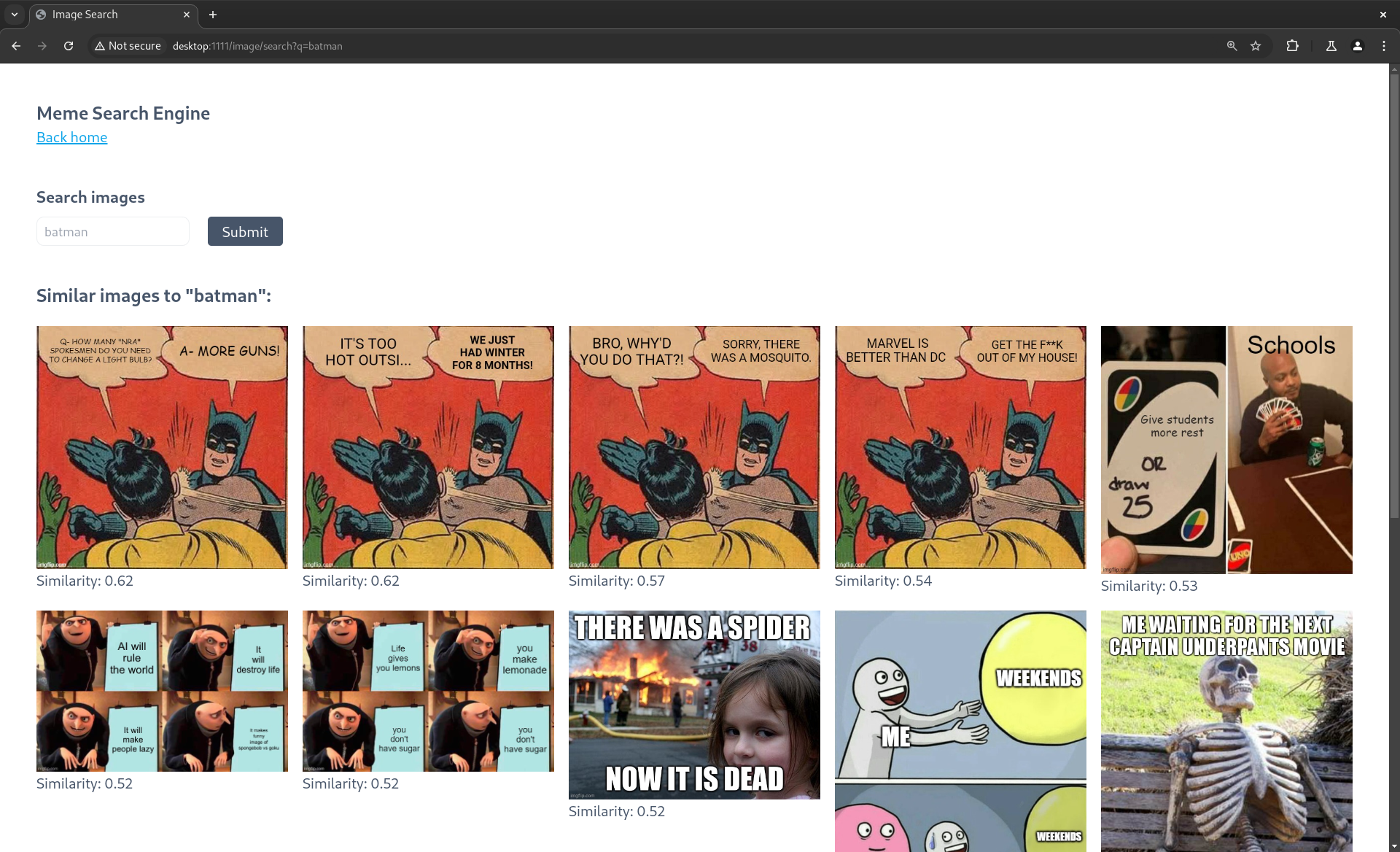
The following figures show the similar images which distances are above from the query image with ResNet18.



With ResNet18 as the feature extraction model, the search engines is more likely to provide
images that have the same feature composition as the query image even though they are completely different.
Similarly, the following figures show the similar images which distances are above from the query image with ResNet50.



With ResNet50, those query results appearing above are not shown because ResNet50
is capable of capturing more complex features in images.
However, it requires more memory and computational power.
On the other hand, the search engine will be able
to provide more accurate results.
Dimentionality Reduction
With Principal Component Analysis (PCA), the dimensionality of the image features can reduced from to . Consequently, the cosine similarity calculation is sped up and the memory usage is reduced.
{ "type": "line", "data": { "labels": [256, 512, 1024, 2048], "datasets": [ { "label": "Vector Size", "data": [2104, 4152, 8248, 16440], "borderColor": "blue", "fill": true } ] }, "options": { "plugins": { "title": { "display": true, "text": "Vector Size vs. Dimensionality" }, "legend": { "display": true, "position": "bottom" } }, "scales": { "y": { "beginAtZero": true, "title": { "display": true, "text": "Bytes" } } } }}With dimensions, they can explain of the variance in the original dimensions, and the space required is reduced from bytes to bytes. That’s a of size reduction!
Database Integration
By transitioning from JSON to DuckDB and reducing vector dimensions, the search speed is improved significantly while using less RAM and storage. Storing image feature of images with a dimension of in DuckDb would require MB of space, and the time to search for similar images is seconds.
While storing the image features of the same images with a dimension of in DuckDB would require MB of space, and the time to search for similar images is seconds.
Challenges
- Memory usage: The image feature extraction model and a multi-modal model require a lot of memory and computational power.
- Relevant result: Image keyword search sometimes provides irrelevant results due to the nature of a multi-modal language model and the descriptions its generates.
Future Work
- Include SQLModel to manage the database schema and prevent SQL injections.
- Reduce memory usage by using a smaller model for image feature extraction, but still maintain the accuracy of the search results.